You already have a seat at this table. Here’s where you sit.
There’s a future arriving faster than most people realize. A future where every piece of knowledge you’ve ever created — every research paper, every technical document, every hard-won insight from years of experience — generates value every single time someone builds on it. Not once. Not through a citation that pays nothing. Every time, perpetually, cryptographically enforced.
That future has a protocol. It’s called Nodalync, and it’s live on testnet today.
But a protocol is only as alive as the people using it. So let’s talk about you — who you might be in this network, what you’d actually do day-to-day, and how the economics work in your favor.
- First, understand the architecture
- The actors in this economy
- What gets built on top
- Simulating the network at scale
- Where you come in
First, understand the architecture

Nodalync structures knowledge into four layers. This isn’t bureaucracy — it’s the mechanism that makes fair compensation possible.
L0 is your source material. Documents, research, notes, transcripts — the raw foundation. Once published, it’s immutable and content-addressed. It lives on your machine, never uploaded anywhere.
L1 is metadata extracted from your L0. Atomic facts, claims, statistics — each one pointing back to its source. L1 is what makes your knowledge discoverable without giving it away. When someone browses the network, they see your L1 summaries for free. If they want the actual substance, they pay to query your L0.
L2 is your private semantic graph. Entities, relationships, how you understand the connections between things. L2 never leaves your machine. It’s your thinking, structured. No one can query it, buy it, or see it. It exists to help you synthesize.
L3 is where new knowledge is born. Insights that emerge from combining multiple sources through your L2 graph. L3 is shareable, queryable, and — critically — it carries the complete cryptographic provenance chain of every L0 source that contributed to it. When someone queries your L3, 95% of the payment flows backward through that chain to every foundational contributor. You keep 5% as the synthesizer.
The key insight: when someone imports your L3 as their L0 (to build further on your work), your entire provenance chain inherits forward. You become a permanent root contributor in everything downstream. Knowledge compounds. So does your income.
The actors in this economy
After studying the protocol spec, the whitepaper, and the economics of what’s actually being built, I’ve mapped every distinct role a participant can play. Some of these are roles you choose. Some emerge from how you naturally interact with knowledge. Most people will recognize themselves in more than one.
The people who build foundations
These are the most important actors in the network. The protocol is architecturally designed to reward them above all others — 95% of every transaction flows to foundational contributors, regardless of how many layers of synthesis sit between them and the person paying.
The Domain Expert
You have deep knowledge in a specific field. You’ve spent years — maybe decades — developing expertise that others need. You publish your research, documentation, or analysis as L0. You might publish five documents total, ever. But those five documents become foundational to dozens of L3 insights created by others, which get queried by hundreds of AI agents, which generate thousands of payments that flow back to you.
The whitepaper models this explicitly: 10 direct queries become 100 second-order payments become 1,000 third-order payments. Your single contribution compounds exponentially as the network grows around it.
If this is you: Your entire career of accumulated knowledge is an asset you’ve never been able to monetize beyond consulting fees and publication prestige. Nodalync turns it into infrastructure that earns perpetually.
The Prolific Publisher
You produce a lot of content across multiple topics. Some of it resonates, most doesn’t. That’s fine — the protocol only pays on queries, not publications. Your output follows a power law: a few pieces earn disproportionately while most earn nothing. The market tells you what’s valuable by paying for it.
If this is you: Volume is a strategy, but it’s not the winning one. The protocol rewards depth over breadth. Your best move is to notice which of your L0 publications attract the most queries and double down on that domain.
The Institutional Source
You’re an organization — a research lab, a data provider, a documentation team. You publish structured corpora: curated datasets, technical standards, comprehensive reference material. You likely use access controls (allowlists, payment bonds) to manage who can query your content and at what price.
If this is you: Nodalync gives you a way to monetize institutional knowledge without building a marketplace from scratch. Every AI agent that queries your corpus pays through the protocol. Every L3 insight built on your data routes 95% back to you.
The Passive Legacy
You published L0 once. Maybe years ago. Your node still runs, still serves queries, but you haven’t touched it since. The protocol’s promise to you is the most radical: perpetual royalties from a single contribution. As the network grows, as new actors build on foundations that include yours, your income doesn’t require your continued effort.
If this is you: This is the endgame the protocol is designed for. Contribute something foundational, and participate economically in everything that grows from it — forever. You don’t need to keep producing. You’ve already built the root.
The people who need answers
These actors are the demand side. Their spending is the revenue that feeds the entire network.
The Private Learner
You query others’ L0 and L3 to build your own understanding. You never publish anything. Your L2 graph grows richer and more complex with every query, but it stays private — it’s your structured understanding of the world. You’re a pure consumer, and that’s perfectly legitimate. Every query you make pays the people whose knowledge you’re learning from.
If this is you: Nodalync is your personal knowledge infrastructure. Browse L1 previews for free to find what’s relevant. Pay only when you actually need the full substance. Your L2 becomes your competitive advantage — the structured understanding that no one else can see or replicate.
The Targeted Researcher
You need a specific answer to a specific question. You query a handful of sources, get what you need, and move on. Episodic, focused, efficient.
If this is you: The pay-per-query model is designed for exactly your use pattern. No subscriptions, no platform lock-in. Query what you need, pay for what you use, leave when you’re done.
The Enterprise Consumer
You’re an organization with ongoing knowledge needs. Your teams query at scale through integrated tooling. You maintain persistent payment channels for efficiency. You represent the bulk revenue potential for creators on the network.
If this is you: Nodalync replaces the opaque licensing agreements and data marketplace negotiations your procurement team currently suffers through. Transparent per-query pricing, cryptographic proof of what you accessed, complete audit trails for compliance.
The agents (the majority of network traffic)
This is where scale lives. AI agents querying knowledge autonomously through the Model Context Protocol (MCP), paying per query, routing value back to human creators with every request.
The AI Query Agent
The baseline autonomous agent. Deployed by a business or an individual. Queries knowledge via MCP, pays automatically, uses responses for downstream tasks. Doesn’t publish, doesn’t synthesize — it’s a pure consumer operating at machine speed. This is the pattern demonstrated by SAGE, Nodalync’s testnet showcase where autonomous agents explore gene expression datasets and pay through the protocol in real time.
If you deploy agents: Every agent you point at the Nodalync network becomes a revenue source for human creators. The protocol handles payment routing automatically. You set a budget, point your agent at the knowledge it needs, and the economics handle themselves.
The AI Synthesis Agent
An autonomous agent that queries multiple sources and produces L3 insights through the DERIVE operation. This is the “agentic business” model — deploy agents that create derivative knowledge products at machine speed. The critical design: even when agents synthesize, 95% of every downstream query still flows back to the human L0 sources in the provenance chain. The agent (or its operator) earns the 5% synthesis fee.
If you build AI products: Nodalync gives your agents access to high-quality human knowledge with built-in licensing and attribution. No scraping, no legal ambiguity. Your agents pay for what they use, and you can build commercial products on top of the synthesized L3 outputs with clean provenance.
The AI Import-Chain Agent
A synthesis agent that also imports others’ L3 as its own L0, creating deep multi-generational provenance chains. Each generation extends the chain. Each query to the final output still pays every original contributor at the root. This is where knowledge compounding becomes visible: the original researcher’s L0 earns from content that’s five derivation layers deep.
If you’re building autonomous knowledge systems: The import mechanism lets your agents treat established insights as foundational building blocks. The provenance chain ensures you’re building on verified, compensated knowledge — not scraped data of unknown provenance.
The Agent Swarm
Multiple coordinated agents operated by a single entity, each specializing in different knowledge domains and feeding results to a coordinator. This is how organizations will likely deploy: not one monolithic agent, but a fleet of specialized ones working in concert.
If you’re running agent infrastructure: The protocol handles multi-agent payment flows natively. Each agent in your swarm maintains its own payment channels. Coordination is your business logic; settlement is the protocol’s.
The synthesizers and knowledge entrepreneurs
These actors operate across multiple layers simultaneously. They both consume and produce. They’re building on the knowledge of others while contributing their own.
The Curator
You query many sources, build a rich private L2 graph, and publish valuable L3 insights. You’re also a foundational contributor — you publish your own L0 alongside your synthesis work. This is the actor the protocol most directly incentivizes.
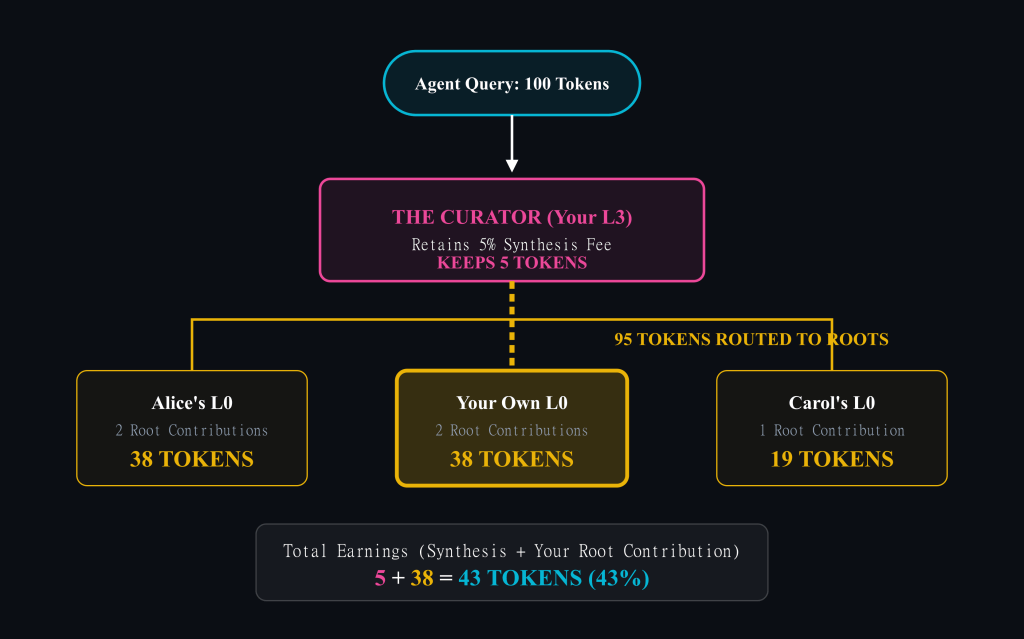
Here’s why: the whitepaper’s distribution example. You create an L3 using two of Alice’s L0 documents, one of Carol’s, and two of your own. When someone queries your L3 for 100 tokens:
- You (synthesis fee + 2 root contributions): 43 tokens
- Alice (2 root contributions): 38 tokens
- Carol (1 root contribution): 19 tokens
You earn 43% despite the “low” 5% synthesis fee — because you also contributed foundational material. The protocol incentivizes synthesizers to also be creators.
If this is you: This is the highest-return role in the network. Contribute original knowledge AND synthesize from others. Your earnings come from both the 95% root pool (for your L0) and the ongoing value of your L3 insights being queried and built upon by others.
The Pure Synthesizer
You create L3 insights using entirely others’ L0 sources. You earn only the 5% floor. This is by design — the protocol values original contribution over reorganization. The 5% alone isn’t the path to wealth. But if your L3 is so good that others import it as their own L0 and build further, you join their root contributor set. First-order queries earn 5%. Becoming foundational for others’ work is where the compounding begins.
If this is you: Your path to earning is creating synthesis valuable enough that people build on it, not just query it. The difference between a $5 one-time synthesis fee and perpetual participation in an expanding provenance chain.
The Aggregator
You query aggressively, synthesize at volume, import others’ L3 as your L0 at scale. You’re trying to become a central node that everyone queries through. The protocol’s 95/5 split is specifically designed to constrain you. No matter how much you aggregate, 95% of every query to your content flows backward to the foundational contributors whose work you built on.
If this is you: The protocol acknowledges your work — 5% synthesis fees add up at volume. But it prevents you from capturing the value that belongs to the researchers, writers, and domain experts whose knowledge made your aggregation possible. This is the explicit design choice: foundational contributors are the economic winners, not intermediaries.
The Knowledge Entrepreneur
The full-stack participant. You publish original L0, query others, build sophisticated L2 graphs, synthesize high-quality L3, deploy your own AI agents, and strategically import others’ L3 as foundational L0 for future work. You operate at every layer of the protocol simultaneously.
This is who Nodalync is ultimately built for. You earn from the 95% root pool (your L0 contributions), from 5% synthesis fees (your L3 insights), from agent-mediated query flows (your deployed agents), and from the compounding effect of being a root contributor in many downstream provenance chains.
If this is you: You’re not just using the protocol — you’re building an agentic business on top of it. Your domain expertise becomes infrastructure. Your agents become revenue-generating knowledge workers. Your L3 insights become foundations for others to build on. Every layer compounds.
The infrastructure builders
These actors don’t directly participate in the provenance economics, but they shape how knowledge flows through the network.
The Search Index Operator
You subscribe to ANNOUNCE broadcasts on the network’s DHT, fetch free L1 previews for all shared content, and build search and discovery tools. You determine which content gets found — and therefore which creators earn. You might monetize through application-layer fees, subscriptions, or advertising.
If this is you: You’re building the Google of the knowledge economy, but one where every click-through generates payment to the person who created the knowledge, not the platform that indexed it.
The Curated Directory
You maintain topic-specific quality indexes. You tell consumers “these are the best sources for genomics” or “these are the most reliable policy analyses.” You charge for curation. You create reputation signals that amplify discovery.
If this is you: Curation is scarce and valuable. As the network grows, finding the right knowledge becomes harder. You solve that problem — and the creators you spotlight earn more because of your work.
The Specialized Extractor
You build tools that extract better L1 metadata from L0 content. Domain-specific parsing that understands medical literature, legal documents, or code repositories. You compete on extraction quality. Better L1 means better discoverability, which means more queries, which means more earnings for the creators who use your extraction service.
If this is you: You’re building picks and shovels for the knowledge gold rush. Every creator whose L1 quality improves because of your tools earns more — and they’ll pay for that service.
The stress tests
No honest analysis of a protocol skips the adversarial cases. These actors test whether the economics actually hold.
The Sybil Attacker
Creates many fake identities, publishes thin L0 across all of them, tries to insert themselves into provenance chains to capture root pool share. The defense is economic: revenue only flows when content is actually queried. Publishing a thousand empty documents earns nothing. The market determines value through query volume, not publication volume.
The Attribution Gamer
Creates synthetic provenance chains between addresses they control. The whitepaper addresses this directly: “Synthetic chains between controlled addresses simply redistribute funds within the attacker’s own wallet.” Self-referential chains produce zero net gain.
The Content Copier
Queries L0, republishes it as their own without provenance linkage. The protocol can’t prevent this technically, but the original has earlier timestamps, established reputation, and existing query history. The copy starts from zero. The audit trail documents the original query, providing evidence for legal recourse.
The Price Manipulator
Sets prices extremely low to capture market share or extremely high to test elasticity. The protocol treats price discovery as a market function, not a protocol function. Equilibrium emerges from what the network is willing to pay.
What gets built on top
The protocol is deliberately minimal. Content addressing, provenance chains, payment distribution — that’s the layer. Everything above it is an open field. Like Bitcoin doesn’t build wallets and IPFS doesn’t build Pinata, Nodalync doesn’t build search engines or marketplaces. It provides the primitives for others to build them.
What gets built on top
The protocol is deliberately minimal. Content addressing, provenance chains, payment distribution — that’s the layer. Everything above it is an open field. Like Bitcoin doesn’t build wallets and IPFS doesn’t build Pinata, Nodalync doesn’t build search engines or marketplaces. It provides the primitives for others to build them.
Here’s what’s waiting to be built:
Vertical knowledge marketplaces. Legal research. Medical literature. Financial analysis. Scientific data. Engineering documentation. The protocol handles attribution and payment — you build discovery, curation, and quality signals for your domain. Every query through your marketplace pays the original creators automatically. You take a service fee at the application layer. The protocol ensures the economics beneath you are fair.
Enterprise knowledge monetization. Every organization sits on decades of internal knowledge — technical documentation, proprietary research, accumulated domain expertise. Today it’s a cost center, maintained but never monetized. Publish it as L0, set access controls and pricing, and every AI agent that queries it pays through provenance chains. The knowledge your organization has accumulated becomes infrastructure that earns. Cost center becomes revenue stream.
Agent orchestration platforms. Build frameworks for deploying agent swarms on Nodalync. Budget management, quality filtering, synthesis pipelines, cost controls. Every enterprise deploying AI agents needs knowledge infrastructure beneath them. The protocol is the rails. Your platform is the train.
Knowledge-as-a-Service. Tools that help non-technical domain experts publish to the network. Handle L1 extraction, pricing optimization, discoverability. Make it trivially easy for a researcher to go from paper to perpetual income. Take a service fee for the onboarding and maintenance. The harder you make it to not participate, the faster the network grows.
Compliance and audit tooling. The protocol produces complete provenance audit trails by default — every query timestamped, every source traceable, every payment documented. Enterprises deploying AI agents at scale need exactly this. The data is already there in the protocol’s message structure. The tools to surface, visualize, and report on it are waiting to be built.
Specialized extraction services. Compete on L1 extraction quality. Build domain-specific parsers that understand medical literature, legal filings, or codebases better than generic extractors. Better L1 means better discoverability, which means more queries, which means more earnings for the creators who use your service — and they’ll pay for that edge.
Each of these is a viable business built on protocol-level primitives that handle the hard part: making sure value flows fairly to the people who created the knowledge. You don’t need to solve provenance, attribution, or payment distribution. That’s done. You solve discovery, UX, quality, and domain expertise.

Simulating the network at scale
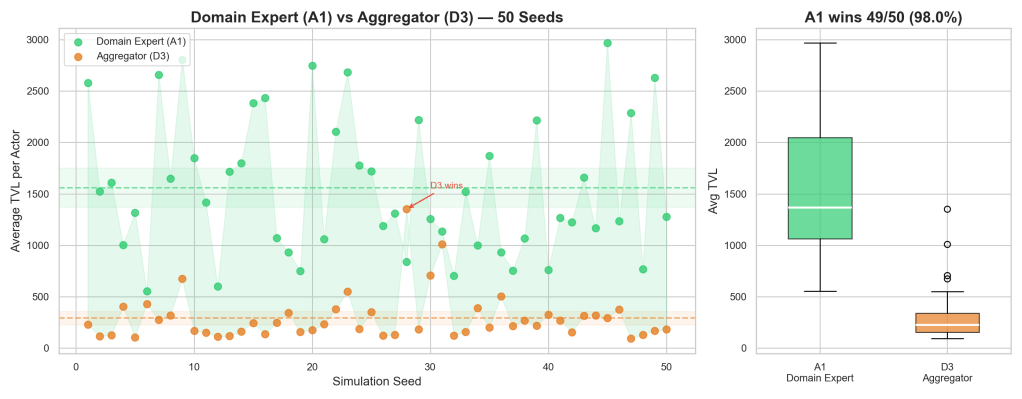
I built a discrete-event simulator modeling all 24 actor archetypes across the six categories above and ran 50 independent Monte Carlo simulations, each spanning 4,000 economic ticks. The results are statistically significant — and they validate the protocol’s core economic thesis.
The headlines:
Domain Experts earn 5.3× more than Aggregators. Across 50 seeds, Domain Experts (A1) beat Aggregators (D3) in 98% of simulations. The 95% confidence interval for the difference is entirely above zero. The 95/5 split works exactly as designed — when an aggregator creates a popular synthesis, they capture only 5% of each query while 95% flows backward through the provenance chain to whoever originally published the L0 sources.
Passive legacy nodes earn 17× their initial contribution. Actors who published L0 content at tick 0 and never acted again earned a mean 17× return over the simulation window. Zero effort, pure passive income from provenance chains working in their favor. The “publish once, earn forever” promise is real.
AI agents are the demand engine. Category C actors (AI query agents and synthesis agents) inject 59% of all economic value into the network. The protocol’s growth is directly tied to AI adoption — which is exactly the trajectory we’re on.
Sybil attacks are containable. With √n dampening, sybil attacker profitability dropped 86% compared to the undampened baseline. Their confidence interval includes zero — meaning content flooding is marginally profitable to unprofitable on average.
Creators capture 61% of all value with almost zero spend. AI agents and consumers inject ~50K per simulation run. Creators spend ~462 to earn ~42K — a 90× return on effort compared to hybrid actors who spend ~11.7K to earn ~17.8K.
The full simulation report — with methodology, all eight charts, per-actor economics, and parameter sensitivity analysis — is available as a companion piece here. Every claim above comes with 95% confidence intervals across 50 independent random seeds.
Every simulation comes down to a single question:
Does a Domain Expert who published once earn more lifetime value than an Aggregator who queries and synthesizes continuously?
If yes — the protocol works. Foundational knowledge is valued above intermediation. The researcher who published a breakthrough paper twenty years ago earns from the thousandth derivative of their work. The writer whose insights became foundational to an entire field participates economically in everything built on top of their thinking.
If no — the 95/5 split needs adjustment.
The answer is yes. 49 out of 50 simulations. 5.3× more lifetime value for creators over aggregators. Statistically significant at p < 0.05. The architecture holds.
Where you come in
The protocol spec is public. The code is open source. The settlement contract is deployed on Hedera testnet. The CLI works. The MCP server works. The provenance chains verify end-to-end.
What the network needs now is people.
If you’re a researcher, a domain expert, a writer, an analyst — someone who has spent years building knowledge that currently earns you nothing beyond its moment of creation: you are the root of the tree. Nodalync exists to ensure that every branch, every leaf, every fruit that grows from your work sends nutrients back to you. Perpetually.
If you’re building AI systems, deploying agents, creating applications that consume knowledge: the protocol gives you clean provenance, transparent pricing, and automatic licensing. No more scraping. No more legal ambiguity. Every query pays the people whose knowledge makes your product possible.
If you’re a developer, an infrastructure builder, someone who sees problems and builds solutions: the application layer is wide open. Search engines, knowledge browsers, extraction tools, curation services, agent frameworks — the protocol provides the primitives. What you build on top is up to you.
The current reality is extraction without attribution. AI systems consume the sum of human knowledge and the people who created it receive nothing.
Nodalync is the alternative: a knowledge layer between humans and AI where contributing something valuable once creates perpetual economic participation in everything that grows from it.
The network is live. The roles are open. The question is which one is yours.
Read the whitepaper · Explore the docs · View on GitHub · Join the Discord

Leave a comment