
Machine learning is a versatile tool that has been leveraged across numerous fields and applications, but one particular subfield that has seen rapid development in recent years is Graph Neural Networks (GNNs). This blog post aims to provide an overview of Federated Graph Neural Networks (FedGNNs), a new and exciting application of GNNs that addresses challenges of data privacy and isolation in a distributed learning environment.
The information of this article was sourced from the paper ‘Federated Graph Neural Networks: Overview, Techniques and Challenges’ (Rui Liu, Pengwei Xing, Zichao Deng, Anran Li, Cuntai Guan, Han Yu, 2021).
Graph Neural Networks (GNNs) and Their Applications
GNNs are powerful tools for handling graph-structured data, where data samples are connected by a graph topology. A good example of this is molecular data where atoms act as the nodes, and the bonds connecting them act as the edges in the graph. GNNs can improve the quality of node embedding by considering neighbourhood information extracted from the underlying graph topology.
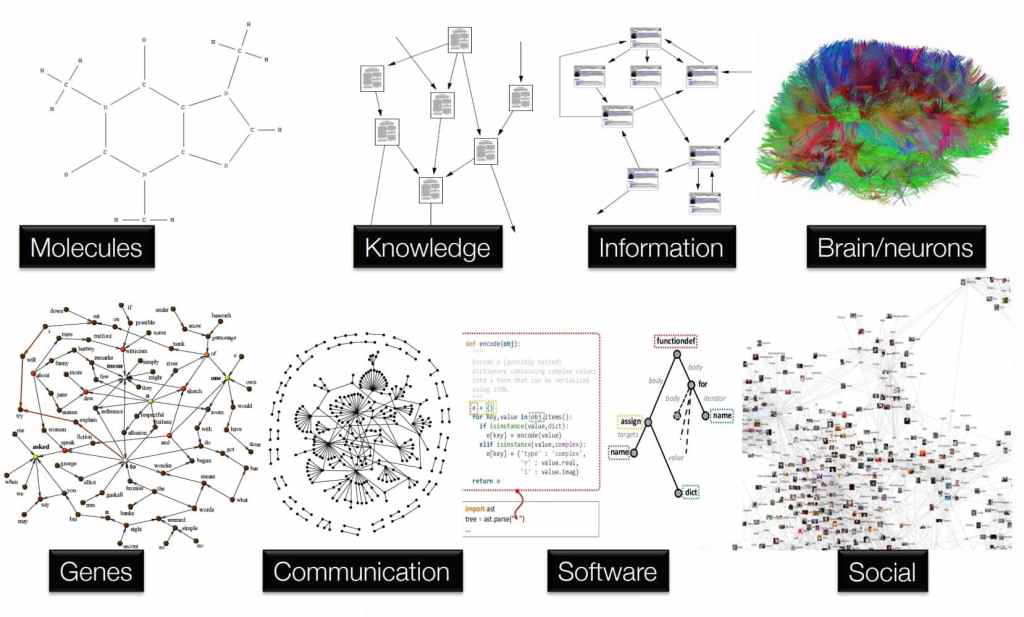
Figure 1: A visual representation of graph neural network applications
The strength of GNNs has led to their wide adoption across diverse applications including drug discovery, neuroscience, social networks, knowledge graphs, recommender systems, and traffic flow prediction. However, a well-trained GNN requires a large amount of training graph data, which may be distributed among multiple data owners in practice.
The Challenge of Data Isolation in GNNs
One of the most significant challenges in training GNNs is data isolation, which stems from the distributed nature of graph data. Due to privacy concerns, data owners (also known as clients) may be unwilling to share their data. Furthermore, the graph data stored by different clients are often non-independent and identically distributed (non-IID), which exacerbates the data isolation issue. Non-IID properties can manifest as differences in graph structures or node feature distributions across clients.
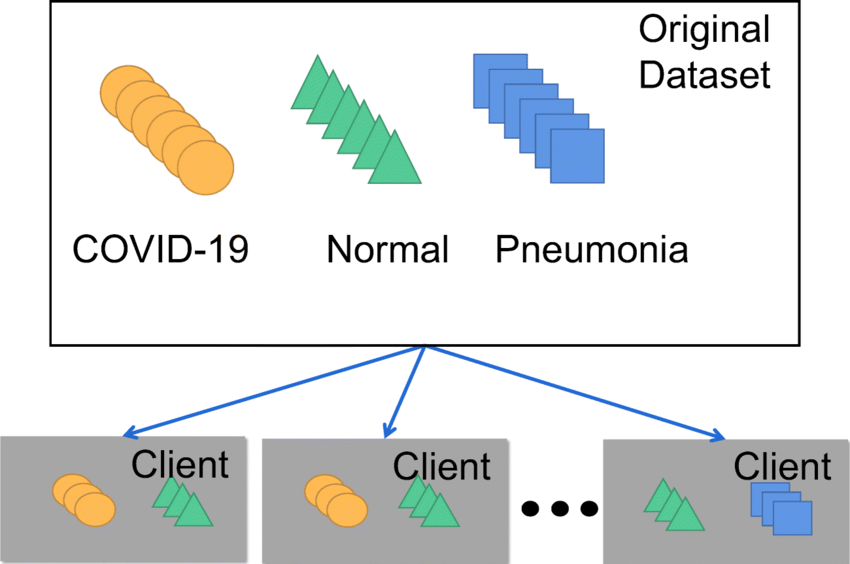
Figure 2: Non-IID data distributions across clients
Federated Learning (FL) as a Solution to Data Isolation
Federated Learning (FL), a distributed collaborative machine learning paradigm, is a promising approach to handle the data isolation challenge. It allows local models to benefit from each other, while keeping local data private. In FL, only model parameters or embedding features are shared among the participants without exposing potentially sensitive local data. This design, combined with various cryptographic techniques, can provide effective protection of local data privacy.
In Federated Learning (FL) scenarios, participants often have relationships with each other, forming a graph topology with participants as nodes. This relationship graph can contain valuable, albeit implicit, information like the participants’ similarities and trust levels. However, harnessing this topology information to improve FL performance is a challenging task. This concept can be understood better by diving deeper into real-world applications, such as those found in the medical and transportation industries.
Medical Industry
In the medical industry, multiple hospitals or healthcare institutions often collaborate on medical research. Each institution has its patient data, which due to privacy regulations, cannot be directly shared with others. This is where Federated Learning comes in, allowing these institutions to learn a shared model without actually sharing the raw data.
The relationship graph in such a scenario could be built on several factors. For instance, the similarity of institutions based on the types of diseases they specialize in treating, their geographical location, or the demographics of their patient base. This information, while not explicitly related to the patient data, could provide valuable context to the learning process.
For example, hospitals in the same geographical area might deal with similar environmental health issues, thus making their local models more relevant to each other. Similarly, institutions specializing in the same disease can have higher trust in each other’s models due to their shared expertise. Leveraging these relationships to weigh the contribution of each local model during the aggregation phase can potentially boost the performance of the federated model.

Figure 3: International FL network for detecting COVID-19 lung anomalies
Transportation Industry
The transportation industry, particularly in the field of import/export and logistic tracking, offers a compelling application for Federated Learning. Various entities like freight companies, shipping lines, and customs offices continuously collect vast amounts of data regarding shipment details, customs procedures, and transit times. However, due to privacy regulations and the sheer volume of data, it’s not practical nor feasible to centralize all this information.
In this scenario, the relationship graph could be built based on factors such as shared shipping routes, the nature of goods being transported, or the frequency of shipments between particular ports. Entities involved in the transportation of similar goods, or those frequently interacting on the same routes, may have more relevant data to each other.
For example, companies specializing in the transportation of perishable goods might face similar challenges related to refrigeration and timely delivery, thus making their local models more applicable to each other. Similarly, entities operating on the same shipping routes might encounter similar weather conditions, port procedures, and transit times.
By considering these relationships, a Federated Learning system could prioritize learning from entities with similar experiences, leading to more accurate model updates. This approach could improve predictions regarding shipment arrival times, optimize route planning, and enhance overall supply chain efficiency.
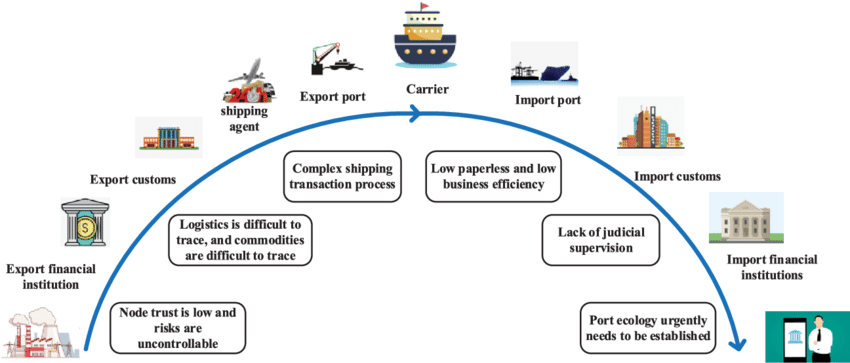
Figure 4: Supply chain improvement areas potentially solved with FL
The challenge lies in effectively identifying and utilizing these implicit relationships to boost the performance of the federated model. Future research in these areas could lead to more efficient and context-aware federated learning systems, pushing the boundaries of what is achievable with distributed machine learning.
Emergence of Federated Graph Neural Networks (FedGNNs)
This confluence of trends in GNNs and Federated Learning has given rise to the field of Federated Graph Neural Networks (FedGNNs). Existing works categorize FedGNNs into three categories: 1) FL clients containing multiple graphs, 2) FL clients containing subgraphs, and 3) FL clients containing one node, based on the distribution of graph data. However, these categories can overlap, and the positioning of these categories has yet to be extensively studied.
In response to these challenges, a recent survey simplifies the three-category taxonomy with a two-category taxonomy based on the location of structural information: 1) structural information existing in the FL clients, and 2) structural information existing between FL clients. However, this new taxonomy still only covers a limited subset of the FedGNNs literature.
In the next part of this blog post, I will delve deeper into the intricacies of FedGNNs, discuss the new two-dimensional (2D) taxonomy that categorizes existing works on FedGNNs, and explore common challenges, methods, and potential limitations. I’ll also review the commonly adopted public datasets and evaluation metrics, and offer suggestions on enhancing FedGNNs experiment design.
A Two-Dimensional Taxonomy for FedGNNs
Despite the challenges in categorizing FedGNNs, a proposed two-dimensional taxonomy offers a fresh perspective. The main taxonomy focuses on how FL and GNNs are integrated together, while the auxiliary taxonomy explores how FedGNNs deal with heterogeneity across FL clients.
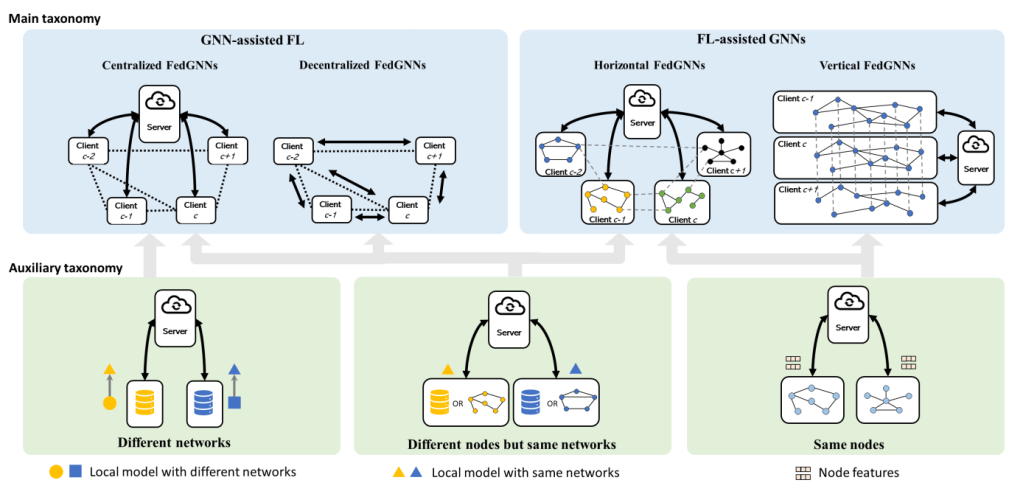
Figure 5: The proposed 2-dimensional taxonomy for FedGNNs research
This 2D taxonomy can provide a structured overview of the FedGNNs field, highlighting specific methods and potential limitations for each category. It serves as a guide to understanding the multifaceted relationships between federated learning, graph neural networks, and the varying data structures they deal with.
Challenges, Techniques, and Limitations of FedGNNs
FedGNNs face numerous challenges due to the non-IID and distributed nature of the data. Differences in graph structures or node feature distributions across clients can affect the effectiveness of the learning process. Specific methods have been developed to tackle these challenges, but they come with potential limitations that need to be considered.
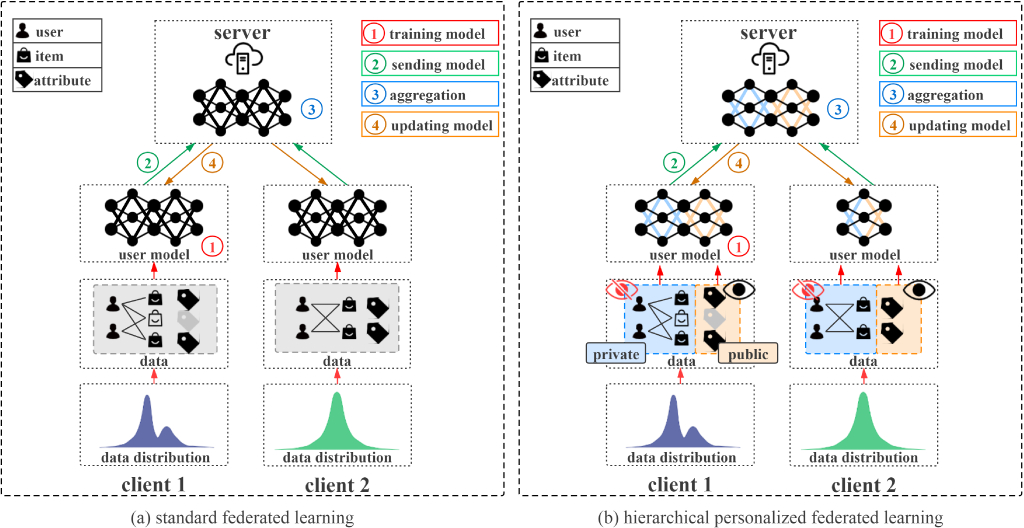
For example, in dealing with the non-IID issue, techniques such as personalized learning (see below figure) and model aggregation can be employed. However, these methods may have limitations in terms of computational efficiency, model complexity, and privacy preservation.
Benchmarking FedGNNs: Datasets and Evaluation Metrics
Benchmarking is essential in progressing the field of FedGNNs, and many studies have adopted public datasets for this purpose. These datasets range from molecular data for drug discovery to social network data for understanding user behaviour. When designing experiments for FedGNNs, it’s crucial to select a dataset that closely aligns with the problem context and model design.

Table 1: Summary of applications, datasets and the corresponding evaluation metrics in FEDGNNs
In addition to datasets, the choice of evaluation metrics is critical. These metrics should accurately reflect the model’s performance in the context of federated learning and graph neural networks. Common metrics include accuracy, precision, recall, and F1 score for classification tasks, and Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and R-squared for regression tasks.
Envisioning the Future of FedGNNs
While FedGNNs have shown great promise, there’s still a long way to go. Future research directions could focus on building more robust, explainable, efficient, fair, inductive, and comprehensive FedGNNs to enhance the trustworthiness of this field. By making FedGNNs more robust and explainable, we can ensure that they perform well under varying conditions and that their predictions can be understood and trusted by users. Additionally, making FedGNNs more efficient and fair will help optimize resource usage and ensure equitable model performance across different groups.
In conclusion, Federated Graph Neural Networks (FedGNNs) represent an exciting and rapidly evolving intersection of Graph Neural Networks and Federated Learning. Despite the challenges in handling non-IID and distributed data, the field has made significant strides in leveraging the strengths of GNNs and FL to provide privacy-preserving and decentralized machine learning solutions. With continued research and development, I look forward to seeing how FedGNNs will further evolve and revolutionize the machine learning landscape.

Leave a comment