
As we stand at the forefront of the Fourth Industrial Revolution, the line between humans and technology is becoming increasingly blurred. One of the technologies gaining prominence in this era is Affective Computing, an interdisciplinary field that seeks to bridge the gap between human emotions and artificial intelligence (AI). In this blog post, we’ll explore some intriguing use cases and areas of research in affective computing, with a special emphasis on speech emotion recognition.
Affective Computing: An Overview
Affective Computing, first coined by Rosalind Picard in 1995, involves systems and devices that can recognize, interpret, process, and simulate human affects (emotions). It’s a rapidly evolving field that combines computer science, psychology, and cognitive science to create machines capable of emulating human emotional intelligence.
This groundbreaking field offers a unique approach to human-computer interaction (HCI), which not only relies on traditional inputs and outputs but also includes the recognition and replication of human emotions.
Use Cases of Affective Computing
Affective computing has an array of applications that promise to transform various sectors of our society.
1. Healthcare
Affective computing can play a pivotal role in mental health care by assisting in the detection and management of mental illnesses like depression and anxiety. For instance, it can be utilized to monitor patients’ emotional states over time, provide therapeutic interactions, or alert healthcare providers if a patient’s emotional state deteriorates.
2. Education
In the education sector, affective computing can be used to develop adaptive learning systems that cater to students’ emotional states. This personalization could potentially enhance learning outcomes by keeping students engaged and reducing frustration.
3. Customer Service
In customer service, affective computing can enable businesses to gauge customer sentiment in real-time, allowing them to provide more personalized and empathetic responses. This can significantly improve customer satisfaction and loyalty.
A Spotlight on Speech Emotion Recognition
Speech emotion recognition (SER) is one of the most fascinating areas of research in affective computing. SER is the process of identifying and classifying human emotions using spoken language. SER systems typically employ machine learning techniques to analyze features such as pitch, tone, speed, and volume of speech.
SER has broad potential applications. It could, for instance, be employed in call centers to monitor customer sentiment and tailor responses accordingly. In a healthcare setting, it could help detect signs of depression or anxiety in patients’ voices. In the automotive industry, SER could be used in intelligent vehicle systems to detect driver stress or fatigue and intervene accordingly.
Despite its potential, SER is a challenging task due to the complexity and variability of human emotions and speech. Research is ongoing to improve the accuracy and reliability of SER systems.
Diving Deeper into Speech Emotion Recognition: Techniques and the Advent of Deep Learning
This process entails various techniques, ranging from feature extraction to the application of machine learning algorithms. With the advent of deep learning and large pre-trained self-supervised models, the landscape of SER is experiencing substantial transformation.
Traditional Techniques in Speech Emotion Recognition
Traditionally, SER involves two main stages: feature extraction and emotion classification.
Feature Extraction: In this stage, various features of the speech signal are extracted, which can provide information about the speaker’s emotional state. These features typically include prosodic features (like pitch, intensity, and speech rate), spectral features (like formant frequencies and bandwidths), and voice quality features (like jitter and shimmer).
Emotion Classification: Once the features have been extracted, they are used to train a machine learning model that can classify different emotional states. Traditional machine learning algorithms used in SER include Support Vector Machines (SVM), K-Nearest Neighbors (KNN), and Gaussian Mixture Models (GMM).
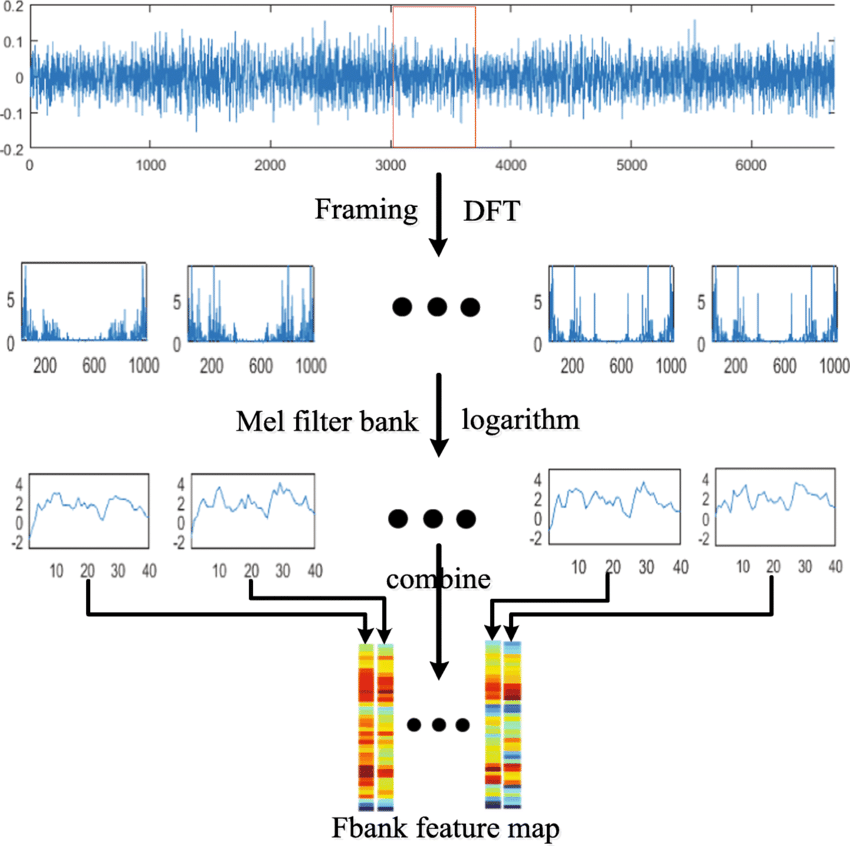
Figure 1. Typical Traditional FBank Feature Extraction Algorithm
The Advent of Deep Learning in SER
The advent of deep learning has revolutionized many fields of artificial intelligence, including SER. Deep learning models, such as Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Long Short-Term Memory (LSTM) networks, and Transformer networks are now being used to improve the accuracy of SER systems.
These models can learn to extract relevant features from raw data automatically, eliminating the need for manual feature extraction. This automatic feature learning capability has made deep learning particularly appealing for SER, where the selection of appropriate features is challenging due to the complexity and variability of human emotions and speech.
Leveraging Large Pre-Trained Self-Supervised Models
In recent years, the use of large pre-trained self-supervised models has emerged as a powerful strategy in machine learning. These models, such as BERT (Bidirectional Encoder Representations from Transformers) for natural language processing and GPT (Generative Pretrained Transformer) for text generation, are initially trained on a large corpus of data in a self-supervised manner, learning to predict a part of the input data from the rest of the data.
Once trained, these models can be fine-tuned on a specific task, like emotion recognition from speech, using a much smaller labeled dataset. This approach, known as transfer learning, allows the model to leverage the vast amount of knowledge it has acquired during pre-training to achieve high performance on the specific task, even with a relatively small amount of labeled data.
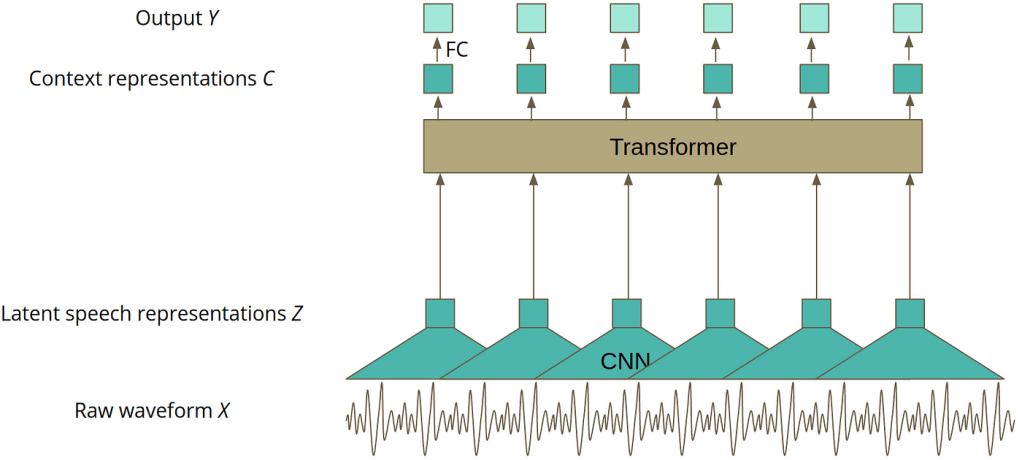
Figure 2. Wav2Vec 2.0 Encoder Architecture Diagram
The exploration and utilization of large pre-trained self-supervised models for SER have indeed led to some remarkable advancements. Notably, models such as Wav2Vec 2.0 and WavLM, pre-trained on extensive volumes of unlabeled audio data, have risen to prominence due to their stellar performance on multiple SER benchmarks.
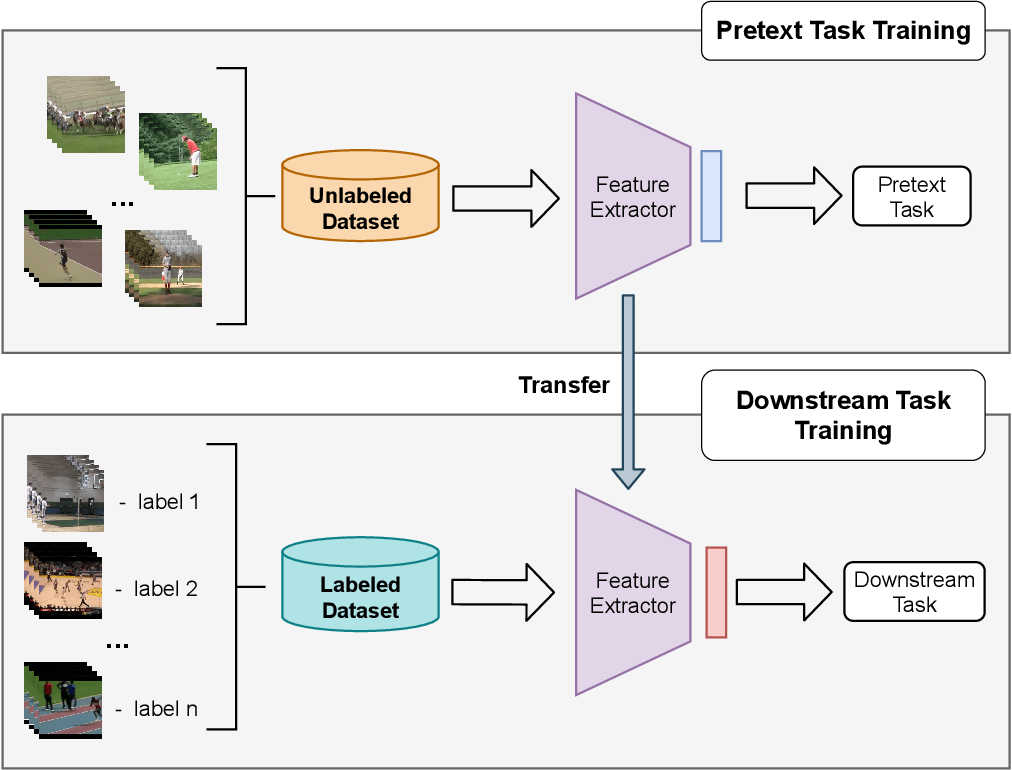
Figure 3. Process of Utilizing A Pre-Trained Self-Supervised Encoder on a Downstream Task
In line with these developments, the introduction of SEIR-DB, one of the largest and most diverse Speech Emotion Recognition (SER) datasets available today, represents a significant stride forward. This vast dataset provides a rich and varied resource, facilitating the training of more robust and accurate models for SER.
One such model that leverages the power of the SEIR-DB is SPEAR – a Speech Emotion Recognition System. SPEAR is an innovative application of a large pre-trained WavLM model, specifically fine-tuned on the SEIR-DB dataset. The WavLM model, as a transformer-based architecture, has demonstrated exceptional prowess in learning representations from raw audio data. When trained on the diverse examples found in the SEIR-DB, SPEAR achieves an impressive test and validation accuracy of 90%.
This high degree of accuracy signifies a leap in the ability of machines to understand and interpret human emotions from speech, opening up new possibilities for real-world applications. From enhancing customer service interactions to improving mental health assessments, the potential use cases are vast and exciting.
The integration of extensive, diverse datasets like SEIR-DB and advanced pre-trained models like WavLM represents the future of Speech Emotion Recognition. This combination facilitates the development of highly accurate SER systems like SPEAR, bringing us closer to fully realizing the immense potential of affective computing.
Current Research Areas in Affective Computing
Current research in affective computing is focusing on improving the reliability and precision of emotion recognition systems. This involves enhancing feature extraction methods, developing more sophisticated machine learning models, and creating larger and more diverse datasets for training these models.
Another area of focus is the ethical implications of affective computing. As these systems become more integrated into our lives, it’s crucial to ensure they are used responsibly and do not infringe on individuals’ privacy or autonomy.
Conclusion
Affective computing is a revolutionary technology with the potential to transform our interaction with machines. As the field continues to evolve, it will undoubtedly open new horizons in our understanding of both human emotion and artificial intelligence.

Leave a comment